Lecture 1
什么是NLP
自然语言处理(NLP)是计算机科学(computer science)、人工智能(artificial intelligence)和语言学(linguistics)这些领域的交叉领域。 它的目的是为了让计算机能够理解语言,来完成对于世界的理解。
NLP的主要流程
下面的图来自知乎用户codingling
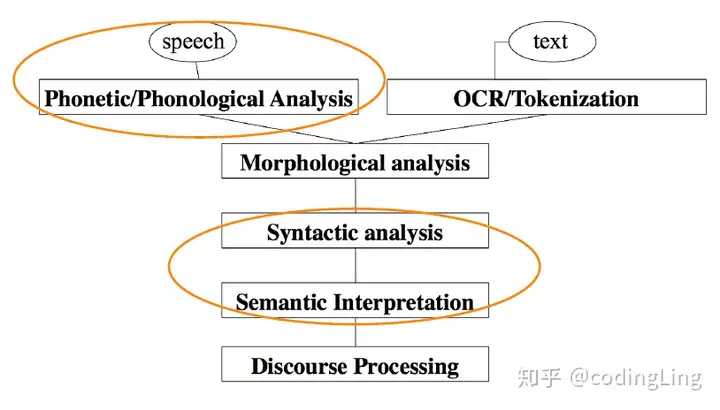
输入是语音和文本,对应的第一层就是语音识别和OCR/分词。第二层是形态学,接下来是句法分析和语法分析,最后的是对话分析。cs224n主要关注语音识别、句法分析和语法分析。前两层完成对于信息的提取,第三层实现句意阐述,最后一层实现对于上下文内容的理解
NLP的难点
NLP任务的难点就在于对于句意的阐释是一个非常困难的问题,往往简单的文字蕴含大量的信息,尤其对于中文而言,在英语语境中,会出现同词不同意,错词不同意的情况
同样在互联网发展的今天,语言本身的意义泛化也让NLP难度变大,尤其是这种无厘头的泛化,一个词语可能会因为与另一个词语音形相似而发生语义迁移,甚至也有可能发生完全相反的对立语义变化
总之,对于语义的理解是一个非常艰巨的任务。
NLP的任务(这部分来自showmeAI的教程部分)
自然语言处理有不同层次的任务,从语言处理到语义解释再到语篇处理。自然语言处理的目标是通过设计算法使得计算机能够“理解”语言,从而能够执行某些特定的任务。不同的任务的难度是不一样的:
- 简单任务 拼写检查 Spell Checking 关键词检索 Keyword Search 同义词查找 Finding Synonyms
- 中级任务 解析来自网站、文档等的信息
- 复杂任务
机器翻译 Machine Translation
语义分析 Semantic Analysis
指代消解 Coreference
问答系统 Question Answering
如何表征词汇
在所有的NLP任务中,第一个也是可以说是最重要的共同点是我们如何将单词表示为任何模型的输入。在这里我们不会讨论早期的自然语言处理工作是将单词视为原子符号 atomic symbols。 为了让大多数的自然语言处理任务能有更好的表现,我们首先需要了解单词之间的相似和不同。有了词向量,我们可以很容易地将其编码到向量本身中。
词向量
这里重点写写
数学符号
先来了解一下序列模型的数学符号命名规则 给出一句话 王刚和李明去上班了 这句话中包含9个字,我们可以将整句话看作一个完整的<1X9>向量,假如说我们的任务是提取其中的人名,那么我们可以设计对应的输出就为一个<1X9>向量,其中为人名组成的为1,不为人名组成的为0。
也就是这样
需要我们预测的语句,也就是原始的输入如何表示呢,我们希望他仍然是向量化的,而且尽可能的保证原有的信息,这里采用基于词表(例如10000大小的vocabulary)映射,使用one-hot的方式对每个单词进行编码。
假如我们拥有一个10000大小的词表
我们可以将输入的每一个部分,都看作是一个1X10000的向量,采用one-hot的思想,出现1的地方也就是该文字在词汇表中的对应位置。
以王刚和李明去上班了这句话举例,这句话在上面的编码思想下就变成了一个<1X9X10000>的一个向量
将输入表示如下
也就是说这里的即为一个1X10000的向量
词嵌入
上面的内容中我们讨论了如何用基于词表(例如10000大小的vocabulary)映射,使用one-hot的方式对每个单词进行编码
这种 one-hot 稀疏单词表征的最大缺点就是每个单词都是独立的、正交的,无法知道不同单词之间的语义相似与关联度。例如「橙子」和「橘子」都是水果,词性相近,但是单从 one-hot 编码上来看,内积为零,无法知道二者的相似性。在自然语言处理的很多任务里,我们更希望能更准确地对词进行向量化表征,覆盖到其语义相似度和分布特性。
比如说词性相近的词语我们希望他们在空间分布上就是接近的,相反的词语他们在空间上就会远一点,这里斯坦福的教授也提到了用向量的内积来表示这一个特征,在数学特征上,相近的词语他们的内积就会大一些。
怎么实现这个特点呢,换用特征化表示方法能够解决这一问题。我们可以通过用语义特征作为维度来表示一个词,因此语义相近的词,其词向量也相近。
语义特征表征的例子如下图所示: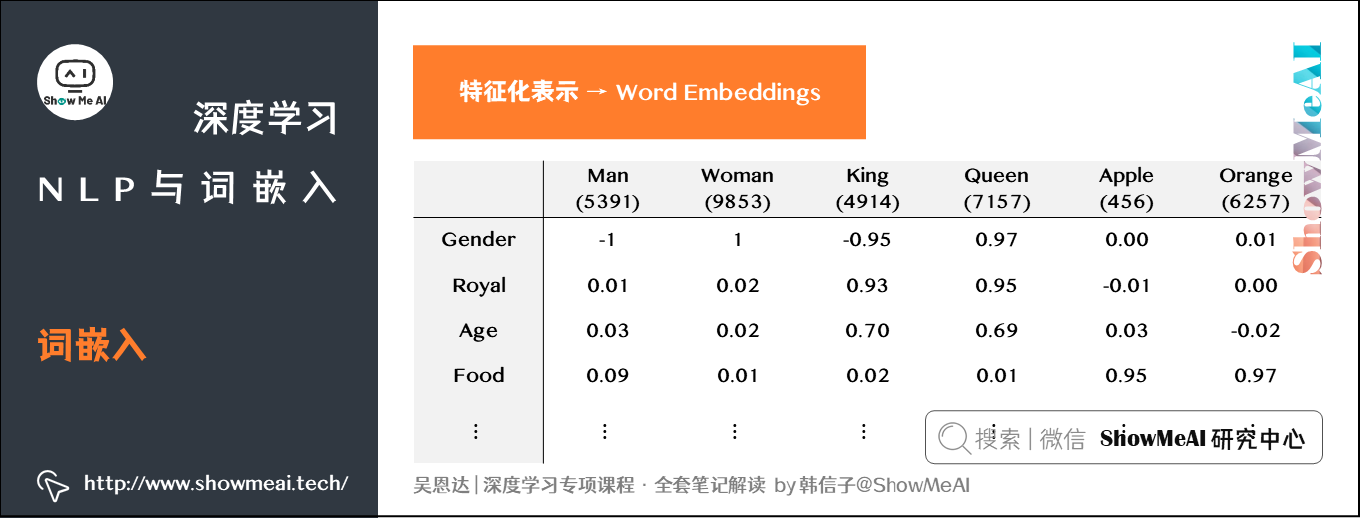
词语义特征表征的长度可以基于场景做不同设定,通常越长能包含的信息越多。假定上图的词特征向量长度设定为300。则词汇表中的每个单词都可以使用对应的300X1的向量来表示,该向量的每个元素表示该单词对应的某个特征值。
这种特征表征的优点是根据特征向量能清晰知道不同单词之间的相似程度,例如「橙子」和「橘子」之间的相似度较高,很可能属于同一类别。这种单词「类别」化的方式,大大提高了有限词汇量的泛化能力。这种特征化单词的操作被称为Word Embeddings,即单词嵌入。
上图的例子仅仅只是一个简单的代表,当我们遇到无法完整表达特征,比较抽象的词语时,我们也完全能够通过扩大特征向量长度来使用别的向量指代原数据向量。