Agent Muti-Agent以及Muti-Agent框架概述
Overview
本次分享介绍的内容
- 1 Agent概念介绍
- 2 已有的Single-Agent与Muti-Agent介绍
- 3 Muti-Agent framework
- 4 总结与趋势
- 5 文章引用
Agent概念介绍
强化学习
强化学习
强化学习(Reinforcement Learning)是一种机器学习方法,它旨在让一个智能体(Agent)通过与环境的交互来学习如何做出决策,以最大化累积奖励或实现特定目标。
为什么要先介绍RL中的Agent呢?
-
一方面是大模型的训练离不开RL的帮助,而基于大模型的Agent与RL也存在关联
-
另一方面是我觉得
目前LLM的Agent概念与RL中的Agent存在很强的相关性 ,所以需要讲讲
强化学习中的概念
-
Agent(智能体):
Agent 是强化学习中的主体,它代表了学习决策的实体。Agent的目标是通过与环境互动,学会选择行动来实现其预定的任务或最大化累积奖励。在RL算法中我们会用Q表,神经网络等来实现这个Agent。 -
环境(env):
环境是Agent操作的背景,它包括Agent可以感知和影响的所有事物。环境可以是现实世界中的物理环境,也可以是虚拟的仿真环境。Agent与环境之间的互动通常通过观测、执行动作和接收奖励来实现。 -
状态(State):
状态是环境的一个描述,它包含了环境的所有关键信息,以便Agent能够做出决策。状态可以是离散的或连续的,具体取决于具体问题。
强化学习中的概念
-
动作(Action):
动作是Agent在环境中执行的操作或决策。Agent需要选择动作来影响环境,以实现其目标或最大化奖励。 -
奖励(Reward):
奖励是一个数值信号,用于评估Agent的行动。奖励通常定义了任务的目标,即Agent应该努力最大化的数量。Agent的目标是通过选择动作来最大化预期累积奖励。 -
策略(Policy):
策略定义了Agent在给定状态下选择动作的方式。它可以是确定性策略,也可以是随机策略。目标是找到一个最优策略,以使Agent能够在不同状态下最大化累积奖励。
强化学习中的概念
- 价值函数(Value Function):
价值函数用于评估状态或状态-动作对的价值,即在特定状态下或采取特定动作后,Agent可以望获得多少累积奖励。值函数有两种类型:状态值函数(V函数)和动作值函数(Q函数)。
总结
对于强化学习,我们需要让一个神经网络(或者说智能体)在特定的决策空间中找出一条奖励最高的路径,我们把这样一个探索+学习后得到的神经网络就成为强化学习中的Agent。
这个Agent它应该拥有拥有感知环境的能力(与环境交互获得反馈),自主决策(在有限的决策空间内),长远来看还有规划行动的能力,也就是它会学习出一个最优的policy。
LLM出现后的Agent
Agent 范式
old Agent = LLMS + Memory + Tools
new Agent = LLMS + Memory + Planning + Feedback + Tools
Agent决策流程
感知(Perception)→ 规划(Planning)→ 行动(Action)→ 获得反馈(Feedback)
-
感知(Perception)是指Agent从环境中收集信息并从中提取相关知识的能力。
-
规划(Planning)是指Agent为了某一目标而作出的决策过程。
-
行动(Action)是指基于环境和规划做出的动作。
-
获得反馈(Feedback)是指Agent应该能够感知到自己决策的结果
Agent决策流程

LLM更像原始人

有一个很有意思的比喻是
我们把LLM也就是大语言模型本省比作一个疯狂原始人
它可能有一些智能,因为它掌握了基本的生存能力,会做简单的算术,但是还远远谈不到聪明,它没有办法完成基础之上更复杂的任务
让LLM变聪明
怎么让这个LLM变聪明呢?
就像原始人发展到现代社会一样,我们的祖先学会使用火(Tools),接着学会把这项经验传递(Memory),现在这个LLM已经能完成非常多本来不能够完成的任务了
这基本上就是old Agent范式
old Agent = LLMS + Memory + Tools
能不能让Agent变得更聪明?
现在我们有一个能记住命令,又有工具的原始人
我们需要他去完成某项任务

能不能让Agent变得更聪明?
一种方法是,我们可以对LLM做特定任务上的微调
我们把让LLM在它原有的基础上再去获取一些垂直领域的知识
另一种方法是,我们为他增加额外的RAG,也就是知识库,来提升它的能力
Lets Think Step By Step
有一些任务是他本身简单思考就能够完成的,比如帮我总结某个网页内容,观察某段代码的运行结果
还有一些任务,我们可以像父母引导孩子一样(第一次走路?)引导他以一种step by step 的方式
把大象装进冰箱需要几步?
现在进化为使用CoT,ToT,GoT等方法来完成这个目标,而这些方法都基于通用问题求解器,也就是GPS思想的指导
Lets Think Step By Step
将一些复杂的任务一步一步的简单化后,这些子问题已经能够被LLM自己解决了
比如这个原始人可能只能搞定10以内的加法,但是其实像9999989899+45464113134564这类复杂的问题也可以被拆成一个一个10以内的加法来完成。
通过高效的组织架构,我们可以让不那么聪明(或者说还在持续进化)的大模型提前拥有解决本身难以解决的复杂问题的能力
Plan的力量
这一部分也就是Agent 他需要完成Planning来帮助他解决这个任务
而planning的结果未必就符合我们的预期,所以我们还需要Feedback反馈给我们结果,然后根据反馈去调整我们的解决问题的方法
所也有一部分设计者们把Feedback也纳入了Planning的范畴之内,也就有这样的范式
Agent = LLMS + Memory + Planning + Tools
总结
对于上面阐述的这些内容,我自己的感受是,Agent 正在一步一步的向真实世界的人类靠拢,他们拥有现实世界中的角色(role)以及任务(task)
他们拥有自己的任务,以上面举到的那个原始人为例,他的角色可能是数学家,而他的任务就是计算9999989899+45464113134564,他可能会采取多种多样的方法完成,比如他要记住题目,向Planner索要Plan,要向别人询问自己的结果是否正确,确认过后他就会把最后的答案端给你了
从数学的角度来看,无论我们写提示词还是对Agent 做COT TOT这样的工作,都是在做决策空间上的压缩,生成一条方便LLM给出答案的路径
已有的Single-Agent与Muti-Agent介绍
Single-Agent
Overview
章节内容
- 1 AutoGPT
- 2 HuggingGPT
- 3 其他的Single-Agent们
AutoGPT
AutoGPT 原名是 EntreprenurGPT
Significant Gravitas 在2023年3月16日表达了他想创造一个实验项目,看看 GPT-4 能否在人类商业世界中生存,简单来说就是是否可以挣钱。其核心思想就是不停的向 GPT-4 发送请求,让其做商业决策,最后根据这个决策执行,看 GPT-4 给的策略能挣多少钱。

AutoGPT
根据 Significant Gravitas 的推文,自从那天之后他每天都在给 EntreprenurGPT 增加能力:包括拥有 long term的记忆、生成子实例完成不同的任务、根据网址返回 404 的错误来重新使用 Google 检索,找到合适的网址等。
该项目在发布 10 天之后开始在 GitHub 上吸引了部分人的注意,此后,AutoGPT 继续迭代,并添加从网页中抽取关键信息的能力,并在3月29日第一次有人 pull request 这个项目。后面陆续增加了语音输入、执行代码等,并在2023年4月3日登顶 GitHub Trending 第一名,开始被大家所熟知
AutoGPT的实现
用一张图来展示
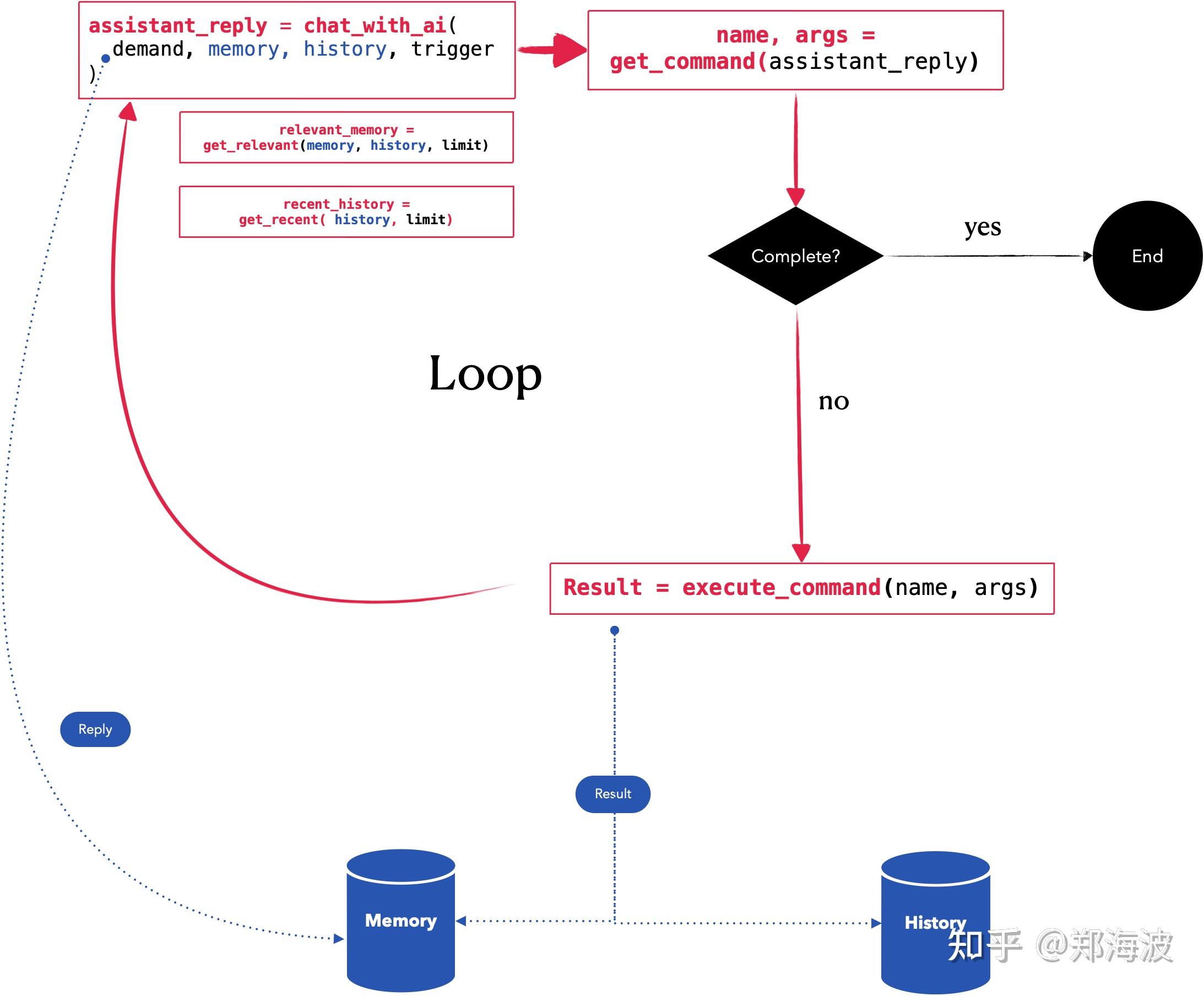
AutoGPT的核心逻辑
如上面那张图演示
AutoGPT 的核心逻辑是一个 Prompt Loop,步骤如下:
AutoGPT 会基于一定策略自动组装 Command Prompt,这些首次会包含用户输入的 Name, Role和Goals Command Prompt 的目标不是为了拿到最终结果,而是通过 GPT Chat API(对应界面Thinking 的过程)返回下一步的 Command (包含name和arguments, 如browser_website(url = “www.baidu.com”) )
这些 Command 都是可扩展的,每一种命令代表一种外部能力(比如爬虫、Google搜索,也包括GPT的能力),通过这些 Command 调用返回的 Result 又会成为到 Command Prompt 的组成元素,回到第 1 步往复循环,直到拿到最终结果结果(状态为“compelete”)
AutoGPT的Command Prompt内容
Command Prompt 的构建是Autogpt成功非常重要的一个部分
内容组成如下:

AutoGPT的Demand
Demand是全程固定不变的部分,它有三个用户输入,也就是AutoGPT开头问你的三个问题(Name、Role和Goals)
我们以网上常见的投资建议作为范例:
Name: Energy-GPT
Role: An AI assistant that helps analyze the best stock opportunities in energy sector
Goals:
Identify top 3 companies to invest in the energy sector based on value
Write report in text file with the pros and cons of that ticker and a summary of how the company earns income
AutoGPT的Demand
上述很像一个Prompt 书写优化,但它不是最终的Prompt,它产生的 Demand Prompt 部分如下面所示:
You are Energy-GPT, An AI assistant that helps analyze the best stock opportunities in energy sector
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
GOALS:
1. Identify top 3 companies to invest in the energy sector based on value
2. Write report in text file with the pros and cons of that ticker and a summary of how the company earns income
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
AutoGPT的Demand
Commands:
1. Google Search: "google", args: "input": "<search>"
2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"
3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"
4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"
5. List GPT Agents: "list_agents", args:
6. Delete GPT Agent: "delete_agent", args: "key": "<key>"
7. Clone Repository: "clone_repository", args: "repository_url": "<url>", "clone_path": "<directory>"
8. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"
9. Read file: "read_file", args: "file": "<file>"
10. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"
11. Delete file: "delete_file", args: "file": "<file>"
12. Search Files: "search_files", args: "directory": "<directory>"
13. Evaluate Code: "evaluate_code", args: "code": "<full_code_string>"
AutoGPT的Demand
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
AutoGPT的Demand
You should only respond in JSON format as described below
Response Format:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted\n- list that conveys\n- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
AutoGPT的Demand
Demand 的组成基本可以总结如下:
- Name,Role,Goals
- Constraints :对GPT声明制约因素,让GPT对AutoGPT产生的提示的一些策略做说明比如4000Token的限制导致会删减History信息,过程中希望它自主完成等等
- Resources :让GPT对可用资源有感知,让其更好的做出策略
- Performance Evaluation: 对GPT提出要求
- 基于过去(Memory和History)反馈进行优化
- 尽量用少的步骤完成目标,减少☆ Long Loop甚至 Infinite Loop的可能
- Commands :基于注册命令,声明GPT可以使用的命令
- Response Format :限制 GPT 返回的格式为包含thoughts 和 command 的JSON格式,方便后续功能的调用
AutoGPT的Memory与History
虽然AutoGPT 工程部分的代码并不复杂,其中的核心其实都是为了更好的管理记忆: Memory 和 History。
其中:
-
Memory是过往记忆存储,使用Embeddings API(Ada) 计算段落向量并保存到本地、Redis或 Pinecone 向量数据库,由于存储的是归一化后的向量,两份段落的向量可以通过点积计算其相关度。
-
History:即历史的 Chat 信息, 会处理成Chat API的消息格式
AutoGPT的Memory与History
通过前面的内容介绍,其实我们应该能注意到一个事实,那就是我们每次告诉AutoGPT的内容长的吓人,大家可能平时处理简单的任务都不会使用这么长的Promp,跟何况,AutoGPT的交互是一个Loop
对于这样步骤多,周期长的交互,而GPT3.5能接受的Token长度显然不够,以 AutoGPT 内部用来获得 Command 建议的 GPT3.5 为例,它就有 4096 的 Token 限制.
那么AutoGPT如何组织自己的Memory与History来实现功能呢?
AutoGPT Token控制的秘密
AutoGPT的做法非常暴力,首先给Memory 写死的 2500 的Token上限,提取与最近9条 Message History 最相关的信息,相关代码如下:
relevant_memory = (
""
if len(full_message_history) == 0
else permanent_memory.get_relevant(str(full_message_history[-9:]), 10)
)
while current_tokens_used > 2500:
# remove memories until we are under 2500 tokens
relevant_memory = relevant_memory[:-1]
(
next_message_to_add_index,
current_tokens_used,
insertion_index,
current_context,
) = generate_context(
prompt, relevant_memory, full_message_history, model
)
AutoGPT Token控制的秘密
其次,剩下的Token除了固定的支出 ( 如 Demand 和 Trigger 部分 ),其余都会给与 History,但实际如果有大范围的查询比如爬虫或 Google 结果的话,History 能进 Command Prompt 的条数不会超过 5 条,相关代码如下
while next_message_to_add_index >= 0:
message_to_add = full_message_history[next_message_to_add_index]
tokens_to_add = token_counter.count_message_tokens(
[message_to_add], model
)
if current_tokens_used + tokens_to_add > send_token_limit:
break
current_context.insert(
insertion_index, full_message_history[next_message_to_add_index]
)
current_tokens_used += tokens_to_add
next_message_to_add_index -= 1
HuggingGPT
3 月 30日,浙江大学、微软亚洲研究院合作发布了基于 ChatGPT的大模型协作系统HuggingGPT,并在 Github 开源了基础代码
他们认为LLM可以充当一个控制器的作用来管理现有的AI模型以解决复杂的AI任务,并且语言可以成为一个通用的接口来启动AI处理这些任务。
基于这个想法,他们提出了HuggingGPT,一个框架用于连接不同的AI模型来解决AI任务。
HuggingGPT
一张图来看看HuggingGPT的工作流程:

HuggingGPT的工作流程
HuggingGPT的工作流程可以被解析为下面几个Stage:
- Task Planning
- Model Selection
- Task Execution
- Response Generation
Task Planning
HuggingGPT在接收到request后,将其解构为一个结构化任务的序列,并且需要识别这些任务之间的依赖关系和执行顺序。
为了让LM做高效的任务规划,HuggingGPT在设计中使用specification-based instruction和demonstration-based parsing
Specification-based Instruction
Task specification提供一个统一的模板来允许LLM进行任务解析。HuggingGPT提供四个槽,分别是task type,task ID,task dependencies和task arguments:
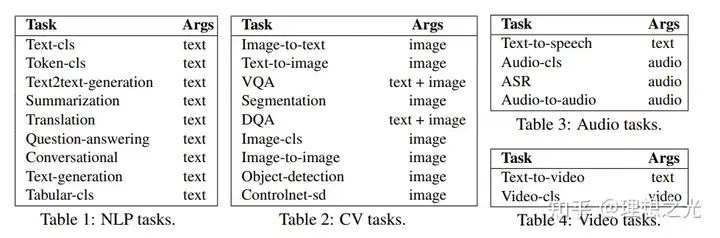
Specification-based Instruction
paper里给了比较明确的提示词与样例:

Demonstration-based Parsing
每个demonstration是一组在任务规划上的输入和输出,输入是用户的请求,输出是期望的任务序列。进一步而言,这些demonstration包含解析任务之间的依赖,有效帮助HuggingGPT理解任务之间的逻辑关系,并且决定执行顺序和资源依赖。
上文的图片里就有相关的内容,生成好的单个的Task,我们需要按照一定的顺序把他们来组织起来得到合理的输出
Model Selection
在解析出任务列表后,HuggingGPT接下来需要将任务和模型进行匹配。为了完成这个任务,首先需要获取专家模型的描述,然后使用in-context task-model assignment来动态选择模型。
-
Model Description:HuggingFace社区中,模型发布者提供的模型描述。
-
In-Context Task-Model Assignment:通过在prompt种加入用户query和解析后的任务,HuggingGPT能够选择最适合这个任务的模型。但是因为字数限制,不可能把所有的模型信息添加在prompt种,所以作者先基于task type过滤模型,并且对剩下的模型根据下载量排序,然后选择top-K个模型作为HuggingGPT的候选模型
Model Selection
paper里同样给了比较明确的提示词与样例:

Task Execution
模型一旦选定,下一个动作就是执行任务。为了加速和计算的稳定性,HuggingGPT在混合推理终端上运行这些模型。
通过将这些任务参数作为输入,模型计算推理结果,然后把它们发回给LLM。为了进一步提高推理效率,没有资源以来的模型将被并行。这意味着多个满足prerequisite dependencies的模型可以同时启动。
怎样保持运行效率?
- Hybrid Endpoint:本地+远程推理
Response Generation
在任务执行结束后,HuggingGPT进行回答生成阶段。在这个阶段,HuggingGPT融合过去三个阶段的答案到一个精简的summary中,包含规划的任务列表、任务选中的模型和模型的推理结果。
其中最重要的是推理结果,以结构化的格式发送给LLM,LLM再生成response返回给user requests。

其他的Single-Agent们
受限于精力,这里我没有把所有的我心目中的Single-Agent介绍完,在这里我列出一些我关注过,并且在将来可能继续做解读的项目,如果您有意愿也可以与我进一步交流:
- Voyager
- RecurrentGPT
- ……
Muti-Agent
Overview
Muti-Agent 与 Single-Agent 的最重要区别:合作!
Single-Agent 在运行的时候可能会寻求其他外部工具的帮助,但这些工具始终是以 Single-Agent 为核心的
Muti-Agent 更像多个独立的人,工作的目的都是为了把事情做好,但大家都有自己的任务,也有自己索求工具的能力,并且,他们还由一定的潜力表现出某种社会学特征
- OvercookedGPT
- XAgent
- ChatDev
- 其他的Muti-Agent们
OvercookedGPT
OvercookedGPT在我看来,是一个最简单的Muti-Agent示例:

OvercookedGPT
OvercookedGPT 的结构与前文里提到的Single-Agent们高度相似

OvercookedGPT
由下面几个基本组件构成:
- delegation planner:Task 拆解
- navigation_planner:action拆解
- recipe_planner:agent的规划
- envs :OPENAI Overcooked ai环境存放
- misc :渲染Overcooked环境组件
OvercookedGPT
Overcooked GPT为什么在我心目中是一个最简单的Muti-Agent示例呢
- 它的实现逻辑并不复杂,Code简单
- 它拥有感知其他Agent的能力,并且在工作上两者相互配合
- Env
- recipe_planner
OvercookedGPT的Env
OvercookedGPT的Env 由 Overcooked-ai 这个OPENAI 提供的gym库魔改而来
Env中声明了这样几个元素
- 环境本身的运行逻辑(reset,step,done)
- action_space
- run_recipes
OvercookedGPT的recipe_planner

ChatDev
今年7月,清华大学 NLP 实验室联合面壁智能、北京邮电大学、布朗大学的研究人员共同发布了一个大模型驱动的全流程自动化软件开发框架 ChatDev (Chat-powered Software Development),加入 OpenBMB 大模型工具体系。
ChatDev 拟作一个由多智能体协作运营的虚拟软件公司,在人类“用户”指定一个具体的任务需求后,不同角色的智能体将进行交互式协同,以生产一个完整软件(包括源代码、环境依赖说明书、用户手册等)。
ChatDev
ChatDev 借鉴软件工程瀑布模型的思想,将其分为:
- 软件设计(Designing)
- 系统开发(Coding)
- 集成测试(Testing)
- 文档编制(Documenting)
之后,通过对软件开发瀑布模型的进一步分解,形成由原子任务构成的交流链(Chat Chain)。
ChatDev

每个环节由不同身份的Agent参与
驱动智能体交流对话的主要机制为:角色专业化(Role Specialization)、记忆流(Memory Stream)、自反思(Self-Reflection)
Role Specialization
像chatgpt等LLM,用户可以使用system prompt等方式来指定角色。
intructor的prompt记为PI, assistent的prompt记为PA。这些prompt会在对话开始之前提供给agent用以指定角色。
角色prompt使用了inception prompt(另一篇paper提出的,也就是一些固定格式的prompt)。
Memory Stream
memory stream能够记录agent历史对话记录,帮助agent后续的决策。
memory stream通过将历史对话进行呈现,保证上下文感知的对话过程,并动态地对对话历史信息进行汇总和决策
Self-Reflection
偶尔会有双方达成一致,但没有触发预定义通信终止协议作为条件的对话。
为了解决这种情况,ChatDev映入了自我反思机制,包括了记忆提取和检索(extracting and retrieving memories)。
系统新加入了一个questioner agent并开启了一个新的对话。questioner将历史对话记录提供给当前的assistant并要求他进行总结
Designing
用户在designing阶段向chatdev输入初始需求,该阶段涉及到3个预定好的角色
- CEO(executive); 2. CPO(product); 3. CTO(technology)
chatchain将此阶段分为多个atomic chat包括:
- software’s modality (CEO and CPO)
- programming language (CEO and CTO)
Coding
coding阶段需要3个预定义角色:
CTO, programmer和art designer。
此阶段chat chain的atomic chat包括:
- generating complete codes (CTO and programmer)
- devising a graphical user interface (designer and programmer)
CTO 会要求programmer使用markdown格式来实现软件系统。art designer则负责GUI生成。
Testing
即使是人类也无法保证一次就写出完美的代码,因此测试时必须的。 ChatDev的测试阶段需要三个角色:programmer, reviewer, 和tester. atomic chat包括:
- peer review (programmer and reviewer)
- system testing (programmer and tester)
ChatDev团队发现让两个agent根据解释器的输出结果相互交流是无法得到一个bug-free的系统的。
作者提出利用thought instruction来改善这个问题tester执行软件,分析错误,提出修改建议,并指导programmer。这个迭代过程一直持续到错误被消除,系统成功运行。
Documenting
在设计、编码和测试阶段之后,ChatDev雇佣了四个Agent(CEO、CPO、CTO和programmer)来生成软件项目文档。
利用 few-shot prompting(包含上下文中的示例)来生成文档。
CTO要求programmer提供环境依赖性的配置说明,生成类似requirements.txt文档。该文档允许用户独立配置环境。
同时,CEO将需求和系统设计传达给CPO,由CPO生成用户手册。
其他的Muti-Agent们
受限于精力,这里我没有把所有的我心目中的Muti-Agent介绍完,在这里我列出一些我关注过,并且在将来可能继续做解读的项目,如果您有意愿也可以与我进一步交流:
- Generative Agents
- Xagent
- MetaGPT
- AutoAgents
- ……
Muti-Agent framework
Overview
随着上文中介绍到的 Muti-Agent正在不断展现出令人震惊的潜力,产出一个高效组织Agent的框架的呼声也越来越大
不管是国内的上海人工智能实验室,讯飞星火,到国外的各级高校,都在探索这个方向的研究。
我们将介绍的工作如下:
- SuperAGI
- Lagent
- AutoSpark
- Camel
SuperAGI

Lagent

AutoSpark

Camel

总结与趋势
总结
在看完了这么多Agent的知识后,大家应该对Agent这个概念有了基本的了解,做一个简单总结就是:
- Agent概念从高度相关的RL中诞生,两者依然存在紧密的联系
- Single Agent 变得越来越智能,社区都在朝着Agent = LLMS + Memory + Planning + Tools的范式寻找自己的解决方案
- Muti Agent 开始崭露头角,更加接近现实中人们的合作方式
- Muti Agent Framework 作为组织 Agent 协作的重要框架开始被人们重视
趋势

目前大家关注的研究方向主要有这些:
- RAG
- Agent 架构
- Agent Framework
文章引用
https://zhuanlan.zhihu.com/p/625094476
https://www.bilibili.com/video/BV1Hz4y1F79p
https://zhuanlan.zhihu.com/p/623045493
https://zhuanlan.zhihu.com/p/659170927