Langchain 介绍
我们来快速回顾一下 Langchain,LangChain 是一个用于开发由语言模型驱动的应用程序框架,从诞生以来,Langchain 就成为了 LLM 开发者几乎必须了解的框架,Langchian 中提出/应用了相当重要的概念如:
- LLMs
- Prompt Templates
- Chains
- Agents and Tools
在他们的设计中 LLMs 用来包装与大模型(包括本地与 API 服务)交互的基本接口,任何模型在使用前都必须被 LLM 类重写,之后就可以按照 langchain 的需要来调用这些模型
Prompt Templates 则是用来帮助生成与大模型交互内容的基本模板,为了避免用户去撰写重复复杂的提示词,langchain 为提示词模板专门设计了一个类来帮助与模型交互
chain 是用户与 llm 交互的基本单位,langchain 选择将用户与 LLM 的一次交互抽象为一个链,链的上游传入文本信息,链的下游输出交互的结果,链是与 langchain 沟通交流的最小单位,同时具有多种类型,包括但不限于用于聊天的 chatchain(在 0.1.0 中被命名为了 llm chain)Retrieval Chain 以及与 Retrieval Chain 区别开的可以持续做检索并交流的 Conversation Retrieval Chain
Agent 在 langchain 初版的设计中被认为是拥有执行工具能力的 llm 交互模块,langchain 0.1.0 在此基础上增加了新的内容,他们主要在工具使用与推理做除了出了新的提升
Tool use: having an LLM call a function or tool Reasoning: how to best enable an LLM to call a tool multiple times, and in what order (or not call a tool at all!)
我个人比较感兴趣的主要是 Reasoning,langchain 的做法是让 LLM 先思考决定要不要使用工具,如果需要那么就返回工具执行的结果,这方面的内容依然还在更新中
LCEL
在介绍 LangchainGraph 前,我想我们有必要先介绍 LCEL
它提供了多种优势,例如一流的流支持、异步支持、优化的并行执行、支持重试和回退、访问中间结果、输入和输出模式以及无缝 LangSmith 跟踪集成
直接看 case
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-4")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
chain.invoke({"topic": "ice cream"})
简单来说(懒得写了)LCEL 提供了替代之前 chain 与 chain 相互连接复杂的格式,用chain = prompt | model | output_parser的方式快速生成一个 Runabel 对象
,大大简化了线性流程的写法
Langchian Graph
LangGraph 的核心组件有下面这些
- StateGraph
- Nodes
- Edges
StateGraph
快速声明一个StateGraph如下:
from langgraph.graph import StateGraph
from typing import TypedDict, List, Annotated
import Operator
class State(TypedDict):
input: str
all_actions: Annotated[List[str], operator.add]
graph = StateGraph(State)
StateGraph 在当前 langgraph 版本中被视为 graph 的核心,上文中声明一个 Stategraph 的同时也声明了这个图的基本信息。input 作为 graph 需要完成 task 的文字描述,all_actions 作为 graph 的动作列表,记录遍历图中采用的所有 action,类型为字符串,可以采用 operator.add 添加内容
class AgentState(TypedDict):
# The input string
input: str
# The list of previous messages in the conversation
chat_history: list[BaseMessage]
# The outcome of a given call to the agent
# Needs `None` as a valid type, since this is what this will start as
agent_outcome: Union[AgentAction, AgentFinish, None]
# List of actions and corresponding observations
# Here we annotate this with `operator.add` to indicate that operations to
# this state should be ADDED to the existing values (not overwrite it)
intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add]
workflow = StateGraph(AgentState)
上面的 case 是 langchain 官方提供的一个更加详细的 StateGraph 的声明实例,
其中 chat_history 代表进入图之前的对话消息,也作为输入传入
intermediate_steps 记录 agent 随时间推移采取的行动列表,将在 agent 的每次迭代中更新,与上面提到的 all_actions 类似,但限制了类型必须为 AgentAction,同时返回这一动作产生的结果(类型为字符串)。
agent_outcome: 这是来自代理的响应,要求为 AgentAction(langchain agent.invoke 的结果) 或 AgentFinish,或者为 None(用于一开始进入图中),这里其实就是限定每个环节的动作结果必须是 agent 的动作或者动作结束 AgentFinish
Nodes
完成图的基本信息初始化后,接下来就是要如何具体去设计图的布局,图中最基本的单位为 Node ,Node 初始化时需要声明这个 Node 的名称以及对应的当数据传入到该节点时的处理方法(可以是 llm 也可以是某个 function),同时 langchain 设计了一个特殊的 Node END 用于结束图的遍历
在图中添加 Node 的方法如下:
graph.add_node("model", model)
graph.add_node("tools", tool_executor)
官方给出的 Node 方法如下:
def run_agent(data):
agent_outcome = agent_runnable.invoke(data)
return {"agent_outcome": agent_outcome}
# Define the function to execute tools
def execute_tools(data):
# Get the most recent agent_outcome - this is the key added in the `agent` above
agent_action = data['agent_outcome']
output = tool_executor.invoke(agent_action)
return {"intermediate_steps": [(agent_action, str(output))]}
Edges
The Starting Edge
构建完节点之后,我们就需要创建边来连接各个节点,因为 Stategraph 中限制了节点与节点间传递的信息类型,我们需要一个单独的方法来确立初始进入的节点,这条专门生成的边也叫做 Starting Edge
用例如下
graph.set_entry_point("model")
Normal Edges
Normal Edges 就是图中最常用的用于连接两节点之间的边,初始化时声明连接的两边就可以,这个边是有向的,从左到右
graph.add_edge("tools", "model")
Conditional Edges
Conditional Edges 是我觉得 langgraph 最棒的设计,从一个节点出发可以连接多个节点,跳转的条件由用户设定的函数返回结果决定
graph.add_conditional_edge(
"model",
should_continue,
{
"end": END,
"continue": "tools"
}
)
在这条边的基础上我们就能够实现很多复杂的功能,包括节点回溯等等
到这里 langgraph 最基本的单元就介绍完毕,看看官方给的一个 example
class AgentState(TypedDict):
# The input string
input: str
# The list of previous messages in the conversation
chat_history: list[BaseMessage]
# The outcome of a given call to the agent
# Needs `None` as a valid type, since this is what this will start as
agent_outcome: Union[AgentAction, AgentFinish, None]
# List of actions and corresponding observations
# Here we annotate this with `operator.add` to indicate that operations to
# this state should be ADDED to the existing values (not overwrite it)
intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add]
def run_agent(data):
agent_outcome = agent_runnable.invoke(data)
return {"agent_outcome": agent_outcome}
# Define the function to execute tools
def execute_tools(data):
# Get the most recent agent_outcome - this is the key added in the `agent` above
agent_action = data['agent_outcome']
output = tool_executor.invoke(agent_action)
return {"intermediate_steps": [(agent_action, str(output))]}
# Define logic that will be used to determine which conditional edge to go down
def should_continue(data):
# If the agent outcome is an AgentFinish, then we return `exit` string
# This will be used when setting up the graph to define the flow
if isinstance(data['agent_outcome'], AgentFinish):
return "end"
# Otherwise, an AgentAction is returned
# Here we return `continue` string
# This will be used when setting up the graph to define the flow
else:
return "continue"
from langgraph.graph import END, StateGraph
# Define a new graph
workflow = StateGraph(AgentState)
# Define the two nodes we will cycle between
workflow.add_node("agent", run_agent)
workflow.add_node("action", execute_tools)
# Set the entrypoint as `agent`
# This means that this node is the first one called
workflow.set_entry_point("agent")
# We now add a conditional edge
workflow.add_conditional_edges(
# First, we define the start node. We use `agent`.
# This means these are the edges taken after the `agent` node is called.
"agent",
# Next, we pass in the function that will determine which node is called next.
should_continue,
# Finally we pass in a mapping.
# The keys are strings, and the values are other nodes.
# END is a special node marking that the graph should finish.
# What will happen is we will call `should_continue`, and then the output of that
# will be matched against the keys in this mapping.
# Based on which one it matches, that node will then be called.
{
# If `tools`, then we call the tool node.
"continue": "action",
# Otherwise we finish.
"end": END
}
)
# We now add a normal edge from `tools` to `agent`.
# This means that after `tools` is called, `agent` node is called next.
workflow.add_edge('action', 'agent')
# Finally, we compile it!
# This compiles it into a LangChain Runnable,
# meaning you can use it as you would any other runnable
app = workflow.compile()
也是比较简单定义了一个 graph,input 与 chat_history 作为输入传入,agent_outcome 与 intermediate_steps 用来限制各个节点之间传入信息的类型,执行顺序是
agent -》决定要不要使用 tool
if 要 -》action -》agent
if 不要 -》END
最后通过 compile()方法将图变为 Runable 类型,之后就可以执行 invoke stream 等等方法了
在此之上的思考
总感觉 langchain 在限制节点之间信息类型的处理办法有点笨拙,应该会有更好的处理办法
之前在 langgraph 的 issue 里翻到了一个很有意思的问题
这对于需要同时理解 LECL 和 langgraph 的用户来说非常困惑。为什么不在 LCEL 中实现 DAG?
我的想法是,因为语法上的问题,首先 LCEL 本身要实现 loop 和 condition 的情况就比较困难,为了避免更冗余的情况(本身 LCEL 就是为了简化线性流程上 langchain 陈旧的繁琐写法),同时 loop 和 condition 这两种情况又非常重要,举几个可能操作场景,我希望 llm 给我一篇技术文稿,完成后我要做审稿修改使他根据我的意见完善自己的创作成果,这时候我们就需要根据人类输入 condition 来判断继续完善内容,重新撰写内容还是结束任务,使用 LCEL 进行线性的 SOP 编排很难实现这样的场景,同时 langgraph 为 SOP 的编排提供了更多天马行空的可能,我们可以覆盖线性,树形,更多可能的应用场景,因此 langgraph 的实现还是非常有必要的
我自己设计的利用langgraph实现TOT的思维导图如下
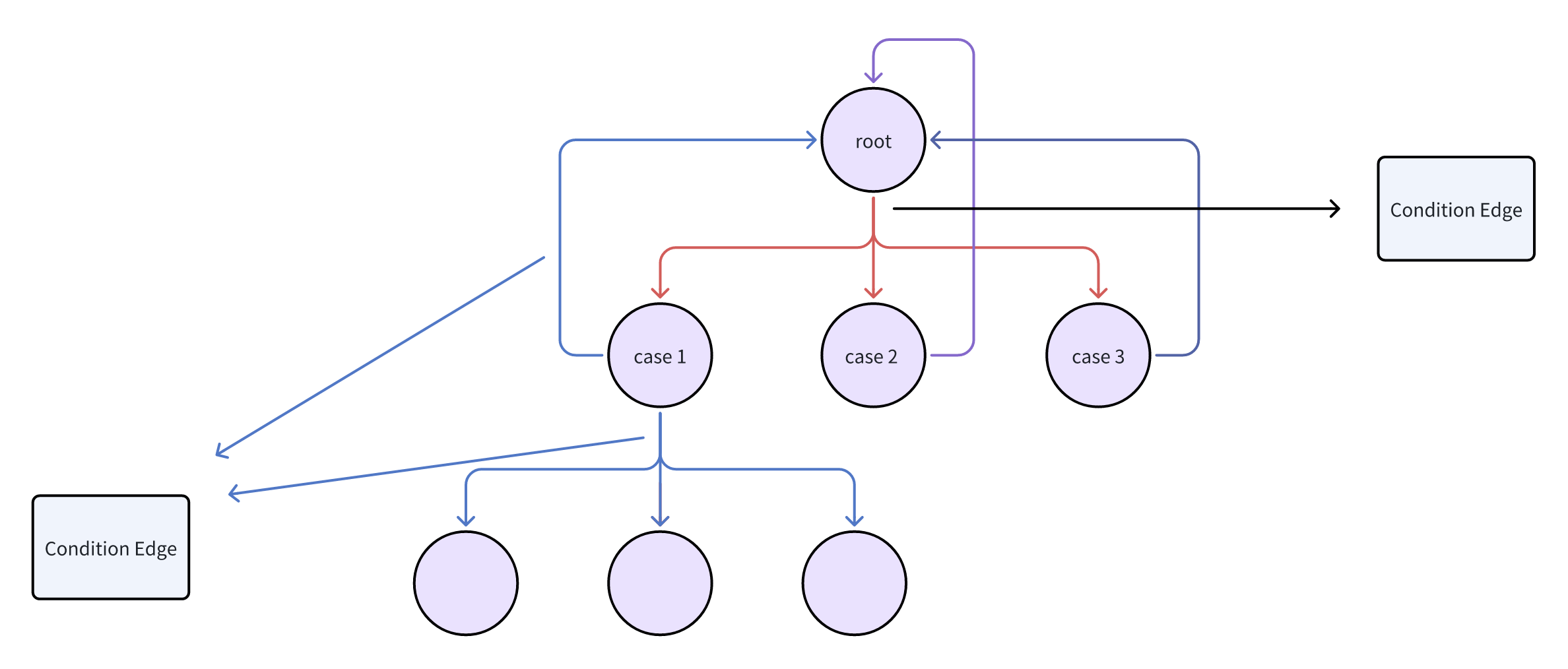
未来 agent framework 可能预见的方向是,我们设立一个行之有效的 role play 框架,利用 profile(角色设定)与 action space(包括角色能够执行的 action node 列表)以及角色自有的 action graph(管理角色要执行的动作行动流程),llm 动态的维护自己当前要执行的 action graph,来确保单个 agent 在复杂生产环境中的稳定性,利用环境中对角色执行的上层 sop 做管理分工来实现我们多种多样的需求,
吐槽
在访问 langchain 与 langgraph 文档的过程中,我遭遇的问题包括但不限于:
-
文档写的像 example,我完全不知道我看完之后有没有彻底了解 lanchain langgraph 的具体内容,花了很多时间去看史山代码,核心内容文档里是完全没有
-
牛魔的 langgraph 给的 case 里面很多参数感觉完全没起作用,源代码也翻不到
-
中文文档就是答辩,一堆机翻